Assembler and defcode
This page explains a bit about how defcode and the uLisp assembler are implemented. The examples are from the ARM version of the assembler, but the RISC-V and AVR versions are very similar.
Introduction
The defcode special form lets you define a form such as:
(defcode name (parameters) body)
where body is either a sequence of numbers, or a sequence of Lisp functions each of which returns a number. The result of executing the defcode form is to write the numbers into an area of RAM, and then save the RAM entry address and the size of the function in a code object. The defcode form then creates a global variable name whose value is a list consisting of the code object, followed by the actual definition.
For example, evaluating:
(defcode mul13 (x) #x210d #x4348 #x4770)
will write the three words #x210d #x4348 #x4770 into RAM. It also sets the global variable mul13 to:
(code (x) 8461 17224 18288)
If the Lisp assembler is loaded, you can achieve the same result by evaluating:
(defcode mul13 (x) ($mov 'r1 13) ($mul 'r0 'r1) ($bx 'lr))
This generates an assembler listing as follows:
0000 210d ($mov 'r1 13) 0002 4348 ($mul 'r0 'r1) 0004 4770 ($bx 'lr)
It also sets the global variable mul13 to:
(code (x) ($mov 'r1 13) ($mul 'r0 'r1) ($bx 'lr))
In either case you can call the function as follows:
> (mul13 11) 143
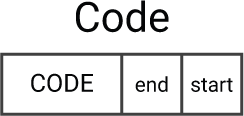
The CODE header
The CODE header is a new type of object that stores the entry point in the lower 16 bits of its cdr, and the size of the code in the upper 16 bits of its cdr. Each of these is aligned to a multiple of four bytes:
The block of RAM is defined as:
#define RAMFUNC __attribute__ ((section (".ramfunctions")))
RAMFUNC uint8_t MyCode[CODESIZE] WORDALIGNED;
where CODESIZE is defined for each platform depending on how much RAM is available. If CODESIZE is zero the assembler routines are commented out using #defines.
The definition of defcode
The defcode special form is defined as follows.
First it checks that the name is a symbol:
object *sp_defcode (object *args, object *env) {
setflag(NOESC);
checkargs(DEFCODE, args);
object *var = first(args);
object *params = second(args);
if (!symbolp(var)) error(DEFCODE, PSTR("not a symbol"), var);
Next it creates symbols for the registers r0, r1 etc:
// Make parameters into synonyms for registers r0, r1, etc
int regn = 0;
while (params != NULL) {
if (regn > 3) error(DEFCODE, PSTR("more than 4 parameters"), var);
object *regpair = cons(car(params), newsymbol((18*40+30+regn)*2560000));
push(regpair,env);
regn++;
params = cdr(params);
}
The call to:
newsymbol((18*40+30+regn)*2560000))
generates the symbol rn, according to the value of regn.
Then it creates the variable *pc* as a local variable, so it can be accessed by the Lisp functions in the body of the defcode form:
// Make *pc* a local variable object *pcpair = cons(newsymbol(pack40((char*)"*pc*\0\0")), number(0)); push(pcpair,env); args = cdr(args);
Initial scan
Then a scan is made through the body of the defcode form checking for symbols, and these are created as local variables for use as labels in the assembler code:
// Make labels into local variables
object *entries = cdr(args);
while (entries != NULL) {
object *arg = first(entries);
if (symbolp(arg)) {
object *pair = cons(arg,number(0));
push(pair,env);
}
entries = cdr(entries);
}
First pass assembly
Then a first pass assembly is performed by calling assemble():
// First pass int origin = 0; int codesize = assemble(1, origin, cdr(args), env, pcpair);
This pass evaluates each of the functions in the body of the defcode, incrementing *pc* accordingly, to check for errors and calculate the size of the generated code, but doesn't actually write any code into RAM. It also writes the value of *pc* into each symbol used as a label.
Allocating RAM for the code
The next step is to check whether the code will fit into the MyCode[] RAM area that has not already been used for machine-code functions. At this stage we're not bothered whether the RAM is fragmented; we simply add up the size of all the gaps:
// See if it will fit
object *globals = GlobalEnv;
while (globals != NULL) {
object *pair = car(globals);
if (pair != NULL && car(pair) != var) { // Exclude me if I already exist
object *codeid = second(pair);
if (codeid->type == CODE) {
codesize = codesize + endblock(codeid) - startblock(codeid);
}
}
globals = cdr(globals);
}
if (codesize > CODESIZE) error(DEFCODE, PSTR("not enough room for code"), var);
If you're using defcode to redefine a function that has already been defined, this approach ensures that the previous definition is still available if the new definition has errors, or won't fit in the available RAM.
Compacting the code area
The next step is to compact the functions in the code area, defragmenting the available space:
// Compact the code block, removing gaps
origin = 0;
object *block;
int smallest;
do {
smallest = CODESIZE;
globals = GlobalEnv;
while (globals != NULL) {
object *pair = car(globals);
if (pair != NULL && car(pair) != var) { // Exclude me if I already exist
object *codeid = second(pair);
if (codeid->type == CODE) {
if (startblock(codeid) < smallest && startblock(codeid) >= origin) {
smallest = startblock(codeid);
block = codeid;
}
}
}
globals = cdr(globals);
}
// Compact fragmentation if necessary
if (smallest == origin) origin = endblock(block); // No gap
else if (smallest < CODESIZE) { // Slide block down
int target = origin;
for (int i=startblock(block); i<endblock(block); i++) {
MyCode[target] = MyCode[i];
target++;
}
block->integer = target<<16 | origin;
origin = target;
}
} while (smallest < CODESIZE);
If a code block is moved, its entry address in the CODE header is updated to its new position.
Second pass assembly
Next, a second pass assembly is performed, which actually writes the code into RAM.:
// Second pass - origin is first free location codesize = assemble(2, origin, cdr(args), env, pcpair);
This also generates an optional assembler listing.
Return the defcode form
The final step is to put the code size and entry address into the code header, and return the name of the machine code function:
object *val = cons(codehead((origin+codesize)<<16 | origin), args); object *pair = value(var->name, GlobalEnv); if (pair != NULL) cdr(pair) = val; else push(cons(var, val), GlobalEnv); clrflag(NOESC); return var;
Assemble function
The function assemble() takes care of each pass of the assembler:
int assemble (int pass, int origin, object *entries, object *env, object *pcpair) {
int pc = 0; cdr(pcpair) = number(pc);
while (entries != NULL) {
object *arg = first(entries);
if (symbolp(arg)) {
if (pass == 2) {
#if defined(assemblerlist)
printhex4(pc, pserial);
pfstring(PSTR(" "), pserial);
printobject(arg, pserial); pln(pserial);
#endif
} else {
object *pair = findvalue(arg, env);
cdr(pair) = number(pc);
}
} else {
object *argval = eval(arg, env);
if (listp(argval)) {
object *arglist = argval;
while (arglist != NULL) {
if (pass == 2) {
putcode(first(arglist), origin, pc);
#if defined(assemblerlist)
if (arglist == argval) superprint(arg, 0, pserial);
pln(pserial);
#endif
}
pc = pc + 2;
cdr(pcpair) = number(pc);
arglist = cdr(arglist);
}
} else if (integerp(argval)) {
if (pass == 2) {
putcode(argval, origin, pc);
#if defined(assemblerlist)
superprint(arg, 0, pserial); pln(pserial);
#endif
}
pc = pc + 2;
cdr(pcpair) = number(pc);
} else error(DEFCODE, PSTR("illegal entry"), arg);
}
entries = cdr(entries);
}
// Round up to multiple of 4 to give code size
if (pc%4 != 0) pc = pc + 4 - pc%4;
return pc;
}
For each of the items in the body of the defcode form can be one of the following options:
- A symbol, such as loop, representing a label in the machine-code program.
On the first pass the value of *pc* is assigned to the variable. On the second pass the label is printed for the assembler listing.
- An integer, such as #x210d, representing a single instruction.
- A Lisp function call to the assembler, such as:
($sub 'r2 'r2 'r1)
This can either return an integer, representing a single word, or a list of values, representing a multi-word instruction. On the first pass this just causes the value of *pc* to be incremented by the correct number of words. On the second pass the instructions are written into memory, and the assembler listing is printed.
Finally the function assemble() returns the total code size.
Calling a code function
If a function created with defcode is evaluated, in eval(), the number of arguments is first checked against the list of parameters, and then call() is called with the entry point of the function:
if (car(function)->type == CODE) {
int n = listlength(DEFCODE, second(function));
if (nargs<n) error2(fname->name, toofewargs);
if (nargs>n) error2(fname->name, toomanyargs);
uint32_t entry = startblock(car(function)) + 1;
pop(GCStack);
return call(entry, n, args, env);
}
The call() function converts each of the parameters to an integer, does a function call to the entry address, and then returns the result as a Lisp integer:
object *call (int entry, int nargs, object *args, object *env) {
(void) env;
int param[4];
for (int i=0; i<nargs; i++) {
object *arg = first(args);
if (integerp(arg)) param[i] = arg->integer;
else param[i] = (uintptr_t)arg;
args = cdr(args);
}
int w = ((intfn_ptr_type)&MyCode[entry])(param[0], param[1], param[2], param[3]);
return number(w);
}
Saving and loading images
The machine-code area is saved with save-image, and loaded back in with load-image, so machine code programs will work correctly without needing to be re-assembled.